MediTwin
Patient Digital Twin platform for clinical trial coordinators to upload protocol PDFs, translate eligibility criteria into structured rules, pre-screen patients, and run forward-looking digital twin simulations with interpretable reasoning traces.
Timeline
Hackathon
Role
Full Stack
Team
Solo
Status
CompletedTechnology Stack
Key Challenges
- Hybrid GenAI and deterministic architecture for reliable eligibility checks
- Groq free-tier rate limits during live protocol extraction
- Clerk JWT verification across a FastAPI backend
- Forward-looking digital twin simulation with persisted reasoning traces
Key Learnings
- Combining LLM reasoning with deterministic computation for clinical reliability
- Supabase PostgreSQL integration with FastAPI and SQLAlchemy
- Building audit-friendly simulation history with interpretable outputs
Overview
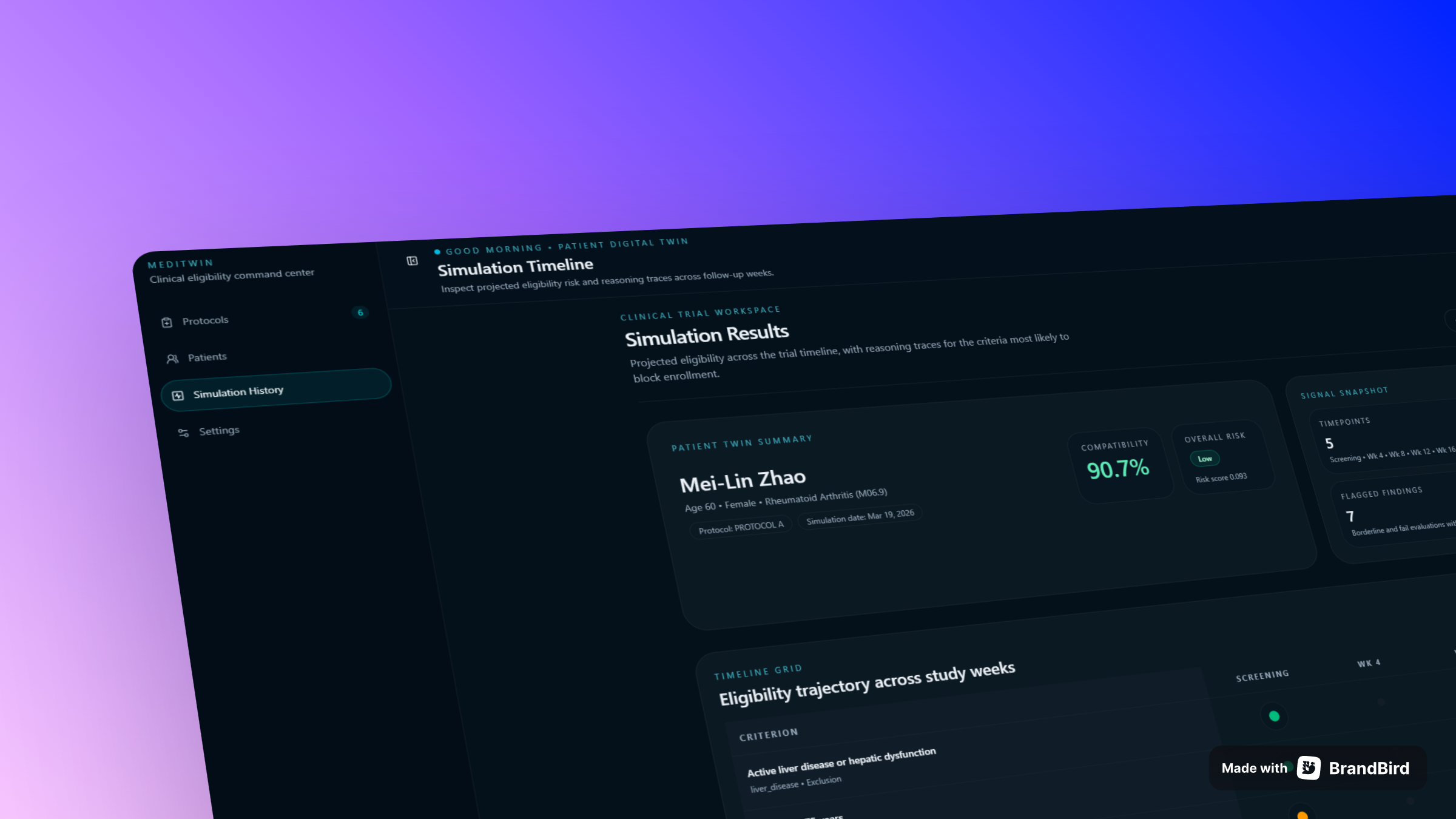
MediTwin is a hackathon project built for clinical trial coordinators. It allows coordinators to upload protocol PDFs, translate natural-language eligibility criteria into structured clinical rules, pre-screen a patient cohort against those rules, and run forward-looking digital twin simulations with interpretable reasoning traces.
The Core Insight
The system uses a hybrid architecture that separates two concerns:
- GenAI (Groq / LLaMA) handles protocol-language understanding and generates coordinator-facing reasoning summaries
- Deterministic computation handles trend fitting, lab value projection, and pass/fail rule evaluation
This split is more reliable than a pure-LLM approach for clinical-style eligibility checks because the numerical evaluation path stays inspectable and repeatable.
Key Features
- Protocol upload and extraction — upload a PDF, Groq extracts and structures the eligibility criteria, coordinator reviews and confirms
- Patient pre-screening — score the full patient cohort against a confirmed protocol, with cached results for repeat checks
- Digital twin simulation — run a full simulation for a patient that projects lab trends and evaluates each criterion with a reasoning trace
- Simulation history — all simulation runs are persisted in Supabase and can be reviewed or replayed from the dashboard
Tech Stack
| Layer | Technology | |---|---| | Frontend | Next.js, TypeScript, Tailwind CSS, shadcn/ui | | Backend | Python, FastAPI, SQLAlchemy | | Database | Supabase (PostgreSQL) | | Auth | Clerk (JWT verification on every API route) | | AI | Groq (LLaMA) for extraction and reasoning | | Deployment | Vercel (frontend), Railway (backend) |
Production URLs
- Frontend: meditwin.vercel.app
- Backend API: meditwin.up.railway.app/api/v1
- API Docs: meditwin.up.railway.app/docs
Known Limitations
- Groq free-tier rate limits can interrupt live extraction at approximately 30 requests per minute
- All patient data in the demo is synthetic — no real patient data is included
- Criteria extraction is LLM-assisted and not perfect; expect roughly 85% accuracy before manual review
What I Learned
MediTwin pushed me to think carefully about where LLMs are and are not trustworthy. Using Groq for language understanding while keeping all numerical evaluation deterministic made the system both practical and auditable — a pattern I would apply to any domain requiring explainability.